From Script to Prototype: Architecting a Multi-Agent Quorum for Financial Sentiment
In the rush to deploy AI, it is easy to grab a pre-trained model off the shelf, run pipeline(), and call it a day. That is how most tutorials work. But as I learned during a recent R&D sprint for my AI engineering group, production reality rarely matches the tutorial.
I have been building a Financial Sentiment Analyzer in my personal R&D sandbox. My goal was to empirically test a simple hypothesis: Can we trust a single Transformer model to understand the entire stock market?
The answer was a resounding “No.” But rather than just reporting the failure, I want to break down the Multi-Agent Architecture I designed to fix it.
The Engineering Problem: Domain Drift
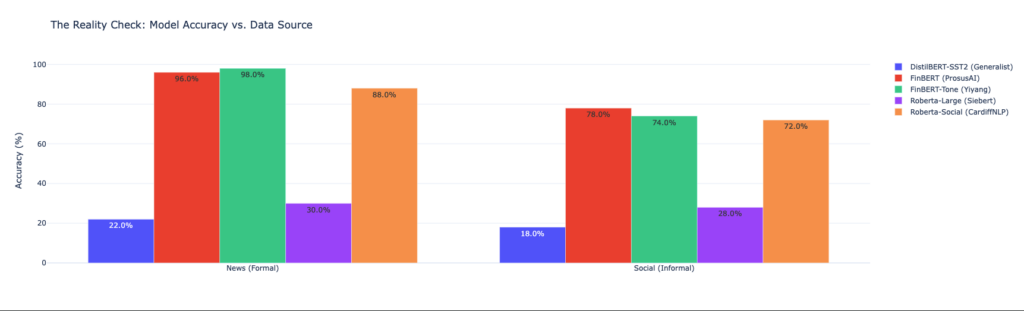
The first phase of my research involved benchmarking standard models like FinBERT. FinBERT is excellent at reading the Wall Street Journal (97% accuracy in my tests). However, when I fed it data from “FinTwit” (Financial Twitter) and Reddit, its accuracy collapsed to ~30%.
This is a classic case of Domain Drift. The model was optimizing for formal grammar and specific vocabulary (“revenue,” “EBITDA”), completely missing the semantic meaning of internet slang (“diamond hands,” “rug pull,” “to the moon”).
A single model architecture was insufficient because the input data was too heterogeneous.
The Solution: The “Agentic Quorum” Pattern
Instead of trying to fine-tune a single massive model to learn every dialect of English, I opted for a Multi-Agent System (MAS) approach. I call this the Agentic Quorum.
The core philosophy is simple: Specialization over Generalization.
1. The Agents
I instantiated three distinct agents, each wrapping a different Hugging Face model:
- Agent A (“The Banker”): Runs
ProsusAI/finbert. It is weighted to trust formal language and ignore noise. - Agent B (“The Socialite”): Runs
twitter-roberta-base-sentiment. It is trained on millions of tweets and understands emoji usage and sarcasm. - Agent C (“The Generalist”): Runs
distilbert-base-uncased. It acts as a baseline tie-breaker.
2. The Consensus Engine
The real engineering challenge was orchestrating these agents. I built a AgentQuorum class that acts as a meta-controller. It doesn’t just average the scores; it looks for consensus.
Here is the pseudocode logic for the arbitration:
- Broadcast: Send the input text to all three agents simultaneously.
- Normalize: Map their disparate outputs (e.g.,
[Label_0, Label_1]vs[Pos, Neg, Neu]) into a standard Enum. - Vote: Calculate the majority vote.
- Conflict Detection: If the “Banker” and “Socialite” violently disagree (e.g., one says Positive, one says Negative), the system flags the data point for manual review rather than polluting the dashboard with a low-confidence score.
The Validation: Benchmark Results
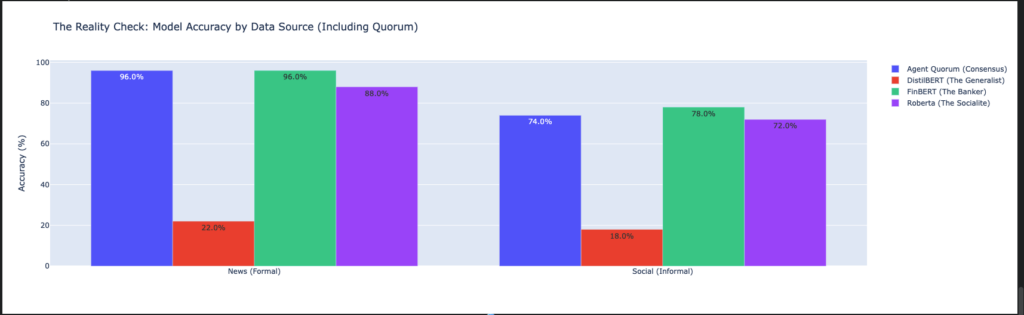
To prove this architecture works, I ran the Quorum against a validation set of 100 samples (50 formal, 50 social). The results, visualized below, confirm the stability of the consensus approach.
- Formal News (Left): The Quorum (Blue) matched the “Banker” (FinBERT – Green) perfectly at 96% accuracy, proving that adding other voices didn’t dilute the expert signal.
- Social Media (Right): The Quorum held strong at 74%, remaining competitive with the specialists and avoiding the catastrophic failure of the “Generalist” model (Red), which scored only 18%.
This chart illustrates the “Safety Net” effect: The Quorum ensures we never rely solely on a model that might be failing (like the Generalist), while capturing the upside of the best-performing specialists.
Why This Matters for Production
This R&D experiment proved that reliability in AI comes from redundancy. By treating models as voted opinions rather than absolute truths, I have designed a prototype that appears resilient to the chaos of social media data.
Initial tests suggest that the “Quorum” architecture can successfully filter out false negatives that would otherwise trigger bad trade signals, validating this as a promising direction for our production build.
Next Steps
The prototype has successfully validated the “Quorum” concept, but the path to a production system is an open question. We are currently evaluating several potential directions:
- Real-time Inference: How do we scale this multi-agent architecture to handle live streaming data without massive latency?
- Generative Explanations: Can we integrate a Generative LLM (like Llama 3) to explain why the agents disagreed, rather than just voting?
- Quantum Specificity: Can we fine-tune an agent to better understand the niche terminology and specific hype cycles unique to the Quantum Computing market?
We are treating this as an active area of research and welcome feedback or collaborators who are interested in these challenges.
You can view the raw code, the benchmarking data, and the Quorum implementation in my GitHub repository below.
View the Repository: Financial Sentiment Analyzer